To enable our project vision, we needed to build a system that is able to detect action items present in a given email, and then summarize them appropriately. We approached these two necessary actions by framing them as two fundamental tasks of Natural Language Processing: text classification and text summarization. Text classification is used to determine which sentences contain action items and text summarization is used to make a succinct summary of each action item.
Check out the "Demo" page to install our extension on your browser.
Under the hood, Extraction uses a text classifier and a text summarizer to perform its signature function (summarizing action items). Therefore, to build Extraction, we required two distinct datasets for training the classifier and the summarizer individually. To curate these two specialized datasets, we drew natural language data from one primary source: the Enron Email Corpus1, a dataset of approximately 500,000 naturally written emails from the Enron Corporation in the early 2000s. It is currently the largest publicly available collection of naturally written language in an organizational setting.
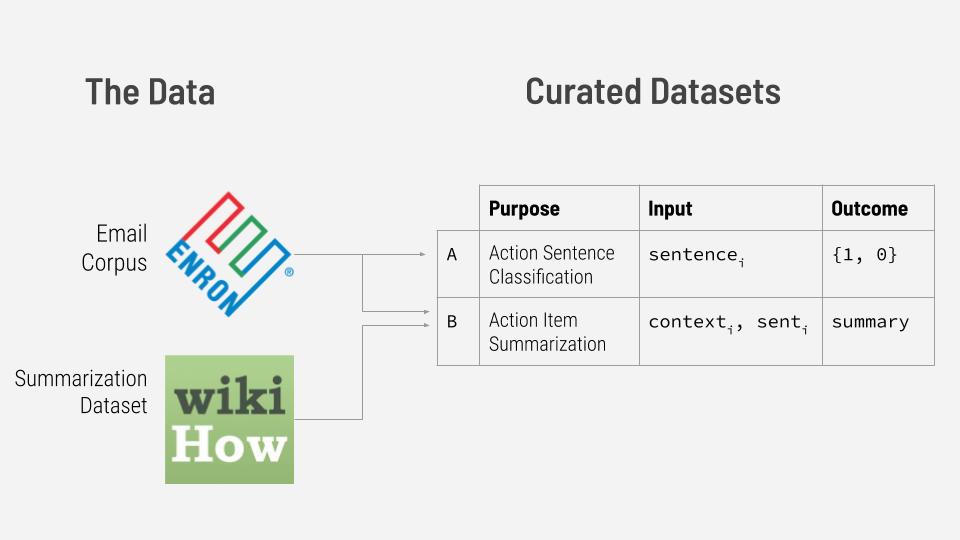
Extraction’s operative text classifier determines whether or not a particular segment of text contains an action item. The segment of text serving as our unit of analysis is the sentence. In other words, the text classifier is trained to evaluate whether a single sentence contains an action item. Although It is possible for multiple distinct action items to be expressed in a single sentence (and also for a single sentence’s action item to depend heavily on previous sentences), according to our preliminary analyses and exploration, the sentence remains the unit most likely to contain exactly one distinct action item. Therefore, we curated a dataset of sentences and their associated labels (1/0) indicating whether there is an action item present in each sentence. We refer to a sentence containing an action item as an action sentence for short.
To create this dataset, we merged several disparate labeled portions of the Enron Corpus. The most important of which is the EPA Dataset2 for addressee tagging created by researchers at Microsoft. The dataset is a list of Enron email messages containing highlighted strings which express tasks to be done by the recipient. We wrote a Python script to parse the EPA data and retrieve the sentence to which the highlighted task belongs as well up to 3 sentences that come before the action sentence. To balance out the action sentences (positives, 1s), we pulled non-action sentences (negatives, 0s) from the Email Intent Dataset3 created by Parakweet Labs as well as the UC Berkeley Enron Email Analysis Project4. The product of merging email sentences from the various sources discussed above is the Action Sentence Detection Dataset, which we then used to train Extraction’s action sentence classifier.
To train an action item summarizer, we curated a dataset which associates action sentences and their preceding sentences with summaries of the action items. We prepended up to three preceding sentences of each action sentence because these preceding sentences tend to contain details that are important to fully understanding the action item.
To curate this dataset, members of our team summarized approximately 4,000 action sentence examples. To make the summaries as generalizable as possible and also minimize the influence of members’ personal linguistic dispositions in the summaries, we adhered to a set of guidelines when summarizing the action items. The primary guiding principles of the guidelines emphasize clarity, conciseness, and extractive-ness (using words present in the input text).
Finally, to supplement our dataset of 4,000 instances we used the Wikihow Dataset5, consisting of WikiHow article paragraphs and summaries for each of them. The WikiHow summaries are amenable to the task of action item summarization because these summaries, like our action item summaries, are in the imperative mood. We use nearly 1 million instances from the WikiHow dataset for pre-training before fine-tuning the model on our own curated dataset.
How does an entire email message get processed and turned into a list of action items? This process can be illustrated conceptually in the 5 steps below.
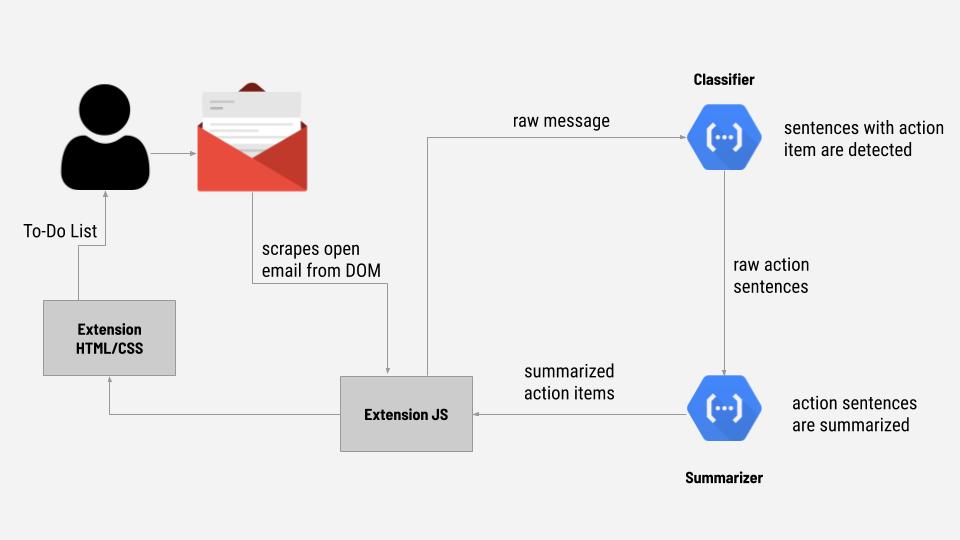
Here's an illustration of how a message is processed from when it gets scraped to when it gets served back to the user in a To-Do list format.
We chose to use fastText, a hierarchical text classification model developed in the Facebook AI Research Lab, as Extraction’s action sentence classifier. We came to this decision after comparing its accuracy and training efficiency to multiple simple baselines, such as logistic regression, SVM and Naive Bayes models, as well as deep learning models. We found fastText to be on par with the deep learning models in terms of accuracy while also being extremely fast and easy to train.
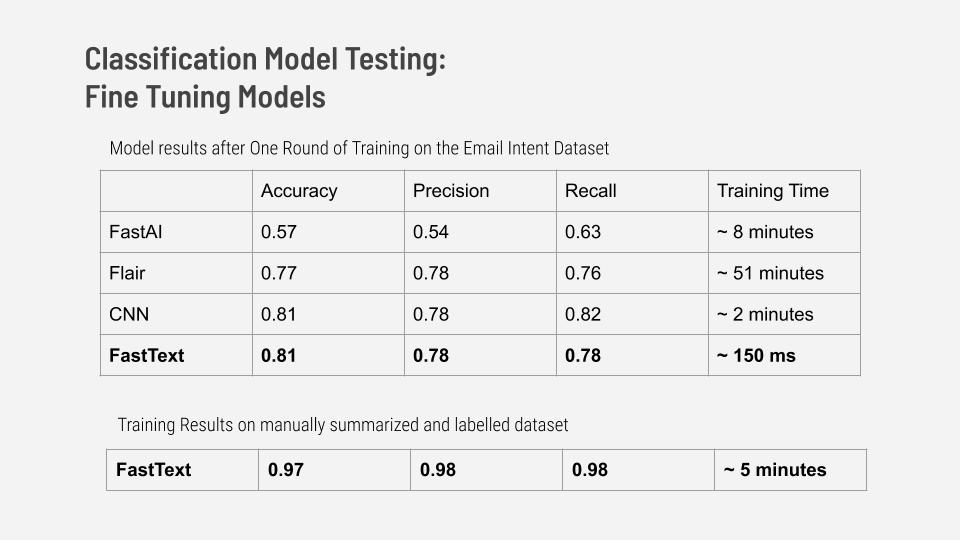
Computational efficiency is especially important for Extraction because the Extraction system will have to perform inference on messages in real time. fastText is efficient on large datasets because it is a hierarchical classifier. Categories are arranged on a tree which reduces training and testing time from linear to logarithmic. Additionally, the tree is built using the Huffman algorithm which leads to more computational efficiency by allowing the model to exploit natural class imbalances.
Because accuracy alone can be a misleading metric if there is class imbalance, we chose to also use precision, recall, and total training times to evaluate different classification models. After selecting the fastText model, we fine-tuned it on our manually labelled dataset as positives. With this model, we achieved an accuracy of 97% with a precision score of 98% and a recall score of 98% on our test set.
After considering both performance and key properties of several state-of-the-art summarization architectures, we settled on using a Pointer-Generator Network6, invented by Abigail See in 2017, to use as a model for summarizing action items. We made this choice because some of the Pointer Generator’s signature properties are particularly favorable to the task of summarizing action items for business professionals.
The Pointer-Generator is both an extractive and an abstractive summarization architecture. When producing a single token as part of a summary, the model chooses between using a token from the input text and using one from the vocabulary it was trained with. Experiments in the literature have shown that, more often than not, the pointer generator chooses to “point” to, or copy, a token from the input sequence. This feature is critical to our task because business email messages are likely to contain important tokens, such as names and emails, which do not occur in the vocabulary used during training.
Take as an example the following action sentence: “Please send a copy of the newest agreement to Rowan Cassius - his number is 415-972-0082”. Chances are good that the tokens “Rowan”, “Cassius” and “415-972-0082” are all outside the training vocabulary, yet they are critical details of the action item. However, this is not a problem for the Pointer-Generator because it can simply point to “Rowan”, then “Cassius”, then “415-972-0082” when producing the a summary such as “Send newest agreement to Rowan Cassius at 415-972-0082.”
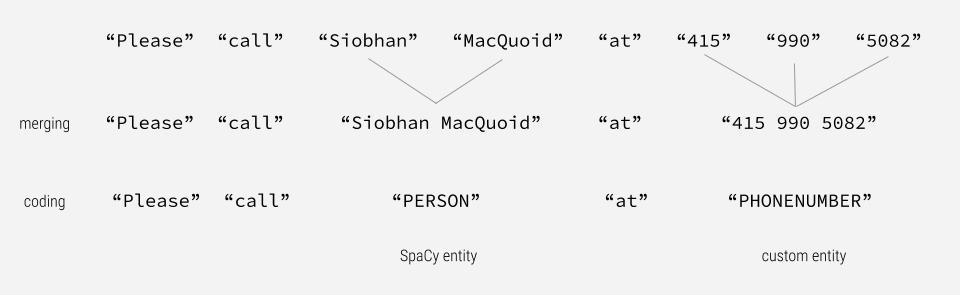
Additionally, we made customizations to the original Pointer-Generator architecture to improve its summarizing performance on email-conveyed action items. These customizations included using pre-trained GloVe word vectors, creating action and context segment embeddings, and implementing customized named entity merging and coding. See below for an illustrated example of how an action sentence undergoes our customized named entity merging and coding.
To track the progress of summarizing accuracy, we use the Rouge-1-F1 score as our primary accuracy metric. This metric measures the word overlap between human-generated summaries and machine-generated summaries. The summarizer that is currently deployed in the Extraction system achieved a Rouge-1-F1 of 64% on unseen examples from the Enron corpus. The image below interprets the model’s current accuracy using the closely related Rouge-1-Precision and Rouge-1-Recall metrics and also displays accuracy progress over several iterations.
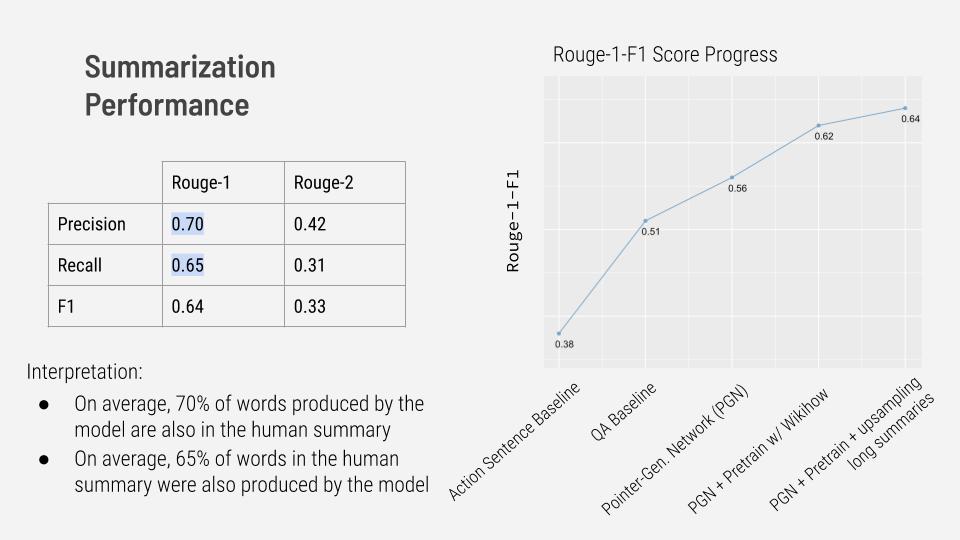
While we are proud of Extraction’s current summarizing ability based on its Rouge-1-F1 score and our experience using Extraction so far. However, we acknowledge that it is necessary to organize a systematic human evaluation of summaries to rigorously quantify and fully understand Extraction’s summarizing ability. A systematic human evaluation is among the Extraction Team’s plans for future improvement.
When it comes to Extraction’s user interface, we wanted to stay true to Extraction’s primary mission of simplifying the lives of its users. As a result, our UI design prioritizes a simple and straightforward user experience and all the features we’ve decided to add were deemed necessary and irreplaceable.
The primary feature of Extraction is the generated list of action items. The user interface’s focus is on the list of action items to make it as easy as possible for users to access this information. We acknowledge the possibility of misclassification or a poor summary, and this is why the extension allows users to easily edit action items after the items are generated. Every feature we decided to include supplements this list, while simultaneously maintaining simplicity of the extension.
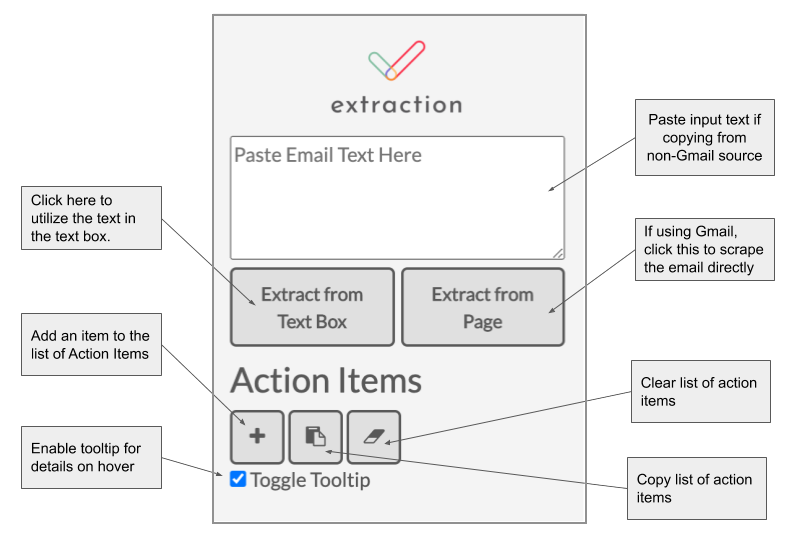
We originally planned on creating a system that could pull a batch of emails at a time and automatically turn them into action items. However, gmail authentication and scraping proved to be a difficult and imprecise task, so we decided to include the text box to allow users to correct possible errors or simply paste emails into the text box and forego the scraping process if they so chose to.
Our final user interface maintains the original design concept of simplicity, while also including all the features we deemed necessary to create a functional and exportable To-Do list.
We conducted a survey of 33 professionals working in Marketing, Consulting, Education, Academia, Technology and other industries to gauge interest in Extraction and learn about respondents’ email and To-Do list usage. In this section we present some of the important survey results.
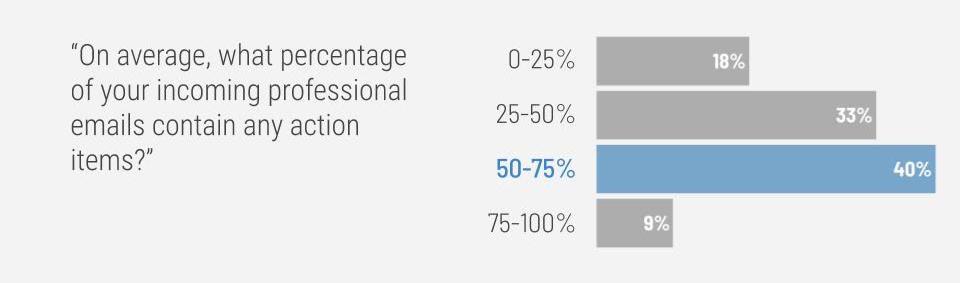
The majority of respondents (40%) said that 50-75% of their incoming professional emails contain action items. This result suggests that Extraction could save many professionals substantial amounts of time if they used Extraction in their daily workflows.
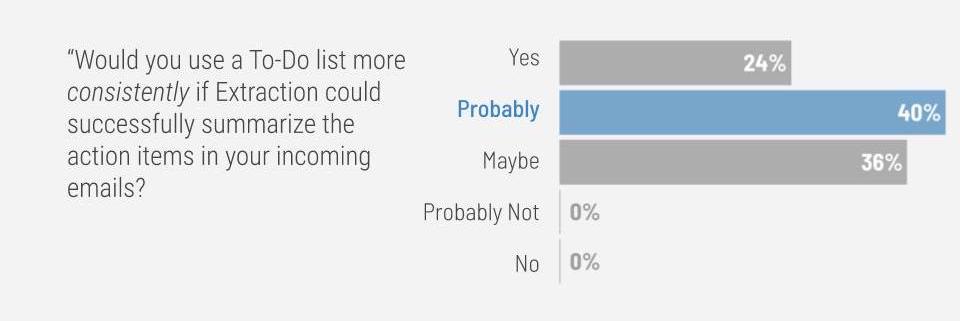
The majority of respondents reported that they would probably update their To-Do lists more consistently if Extraction could successfully summarize the action items in their incoming emails. Moreover, 64% said they either would or probably would. For this reason, we hypothesize that Extraction will also offer users a productivity boost through the pathway of more consistent use of To-Do list.